Democracy and Efficiency
The AI has already proven to work well for many tasks that were not possible to tackle with computers before. Now we’ve entered the scaling phase to make it:
- as accessible as possible (developer tools, explainability, the “democratization of ML”) and
- putting it on as many devices (model efficiency) as possible.
Hence, more and more ready-to-use recipes are created, frameworks are hiding complexity, and, pre-built models are optimized and ready to be served on all kind of devices.
Recommendations
TFRS
This one is huge for the RecSys community. Google adds recommendations package into the tensorflow, that makes building, evaluating, and serving sophisticated recommender models easy (this is to the point of democracy).
This also involves Maciej Kula, author of a couple of hugely popular reco libraries: LightFM and Spotlight. So it promises to be a very elegant API.
And you can see how easy it is to create even a multitask-system. Here is a code snippet to define two learning tasks, one to predict ratings, another to predict the amount of relevant movies:
tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError()],
)
tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128)
)
)Then you can combine these tasks while computing the loss and adjust the weight accordingly. It’s like Lego for recommendations.
LinkedIn’s Intents
A couple of years ago, LinkedIn has joined a cohort of companies that are doing recommendations by intent (members, pages, hashtags, newsletters, etc. in this case) on the main page. Here is a story of how they did it. Some highlights:
- UI framework: to be able to quickly switch between recommendation types in the frontend, a unified framework for all the platforms.
- [Micro]-Services: different services for different recommendations with a unified ranker component on top of them. Allows to quickly plug-and-play different algorithms.
- Unified tracking: so often overlooked but such an important mention.
Efficiency
NVIDIA
Following-up on the last week’s video topic. Building an ML application on top of a video stream is not something easy and requires expertise in multiple domains. So NVIDIA wants to help you make deployment of such kind of applications easier. This also falls into the “democratize” suit. Here is an excerpt from their other article, explaining how to build a real-time face-mask detector application:
To use TLT [NVIDIA’s transfer learning tool] and DeepStream you do not necessarily have to know all the concepts in depth, such as transfer learning, pruning, quantization, and so on. These simple toolkits abstract away the complexities, allowing you to focus on your application.
So the modern-day workflow for the AI video app can look like this:
Download a pretrained model
|
|--> Get data for your use case
|
|--> Retrain (Transfer learning) & Prune
|
|--> Export model and use with DeepStream libraryI want to point the Prune part, which is becoming more and more relevant for the production systems. And there are many ways to do it, some I’ve covered in a previous post, but you can also check NVIDIA’s blog post.
Why is it important? For example, in the face-mask detection example running on a Jetson Nano after pruning the mean average precision has dropped from 86.12 to 85.5%, while frames per second increased more than 3 times — from 6.5 to 21.25.
This doesn’t even feel like a trade-off!
Here is also a free course from them to get started with video analytics: Getting Started with DeepStream for Video Analytics on Jetson Nano.
TFLITE’s NLP
And more on the topic of efficiency. Google has added many things around NLP into the TF Lite.
So that it’s easier to do things like that in your browser: 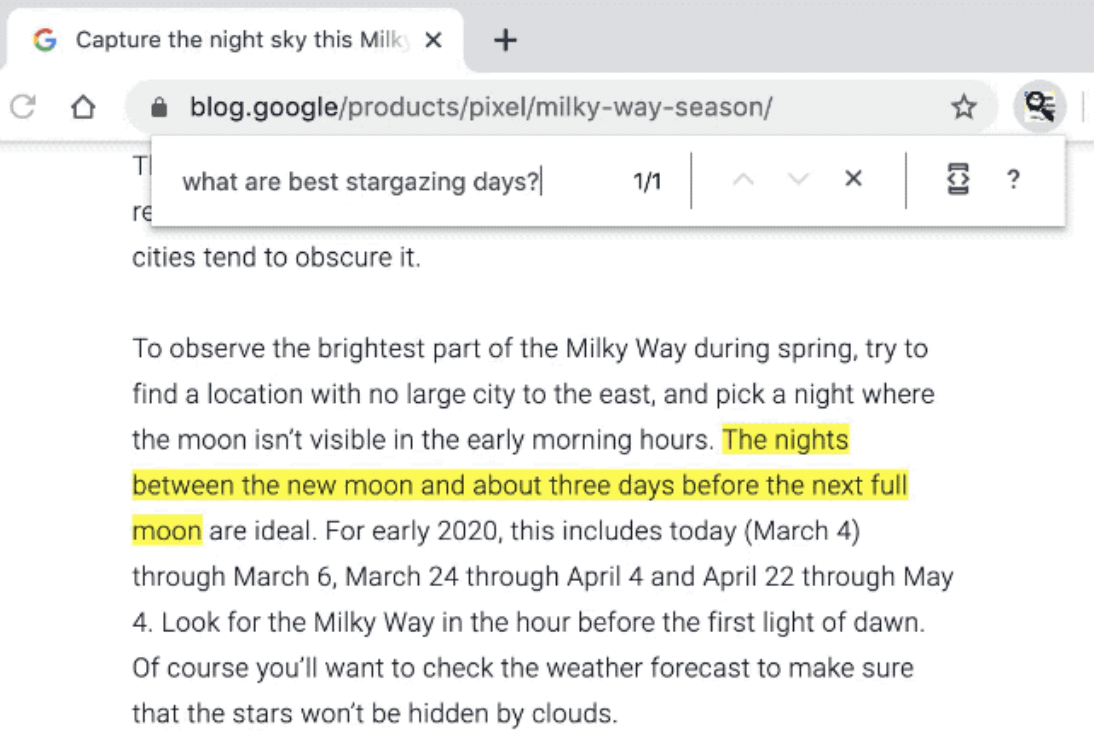
Image from this blog post about the in-browser BERT.
And these capabilities are also unlocked by the pruning and quantization. Just take a look at how much more efficient the model becomes after losing only a fraction in accuracy: 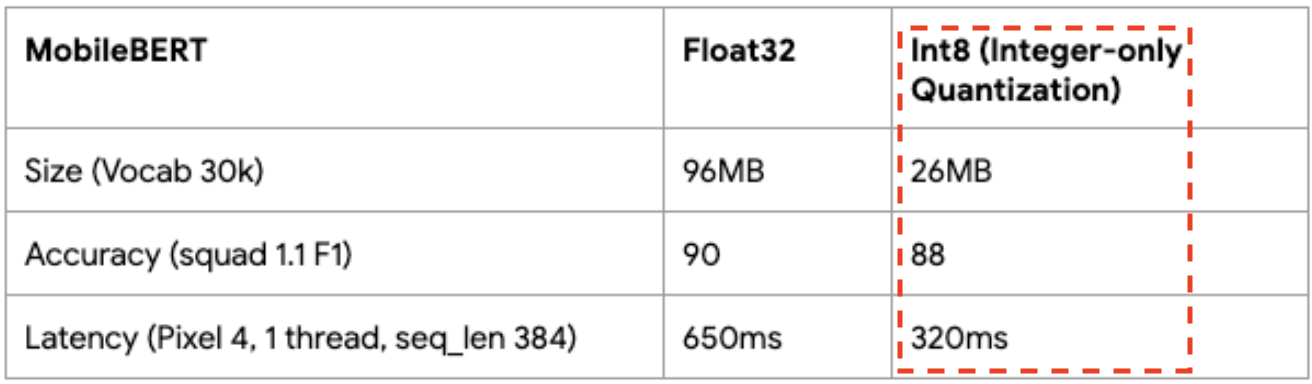
Pixar
And after some philosophy let’s end when it’s best. If you always wondered how would you look like a Pixar character, now you have a chance to see that. As well as an informative conversation with its creator.
Blending humans and cartoons using @Buntworthy's Google Colab notebook. Thank you for that, it's awesome. Here is a YouTube version of this video: https://t.co/7bUd7nXaX3 pic.twitter.com/iG09lpEAXX
— Doron Adler (@Norod78) August 23, 2020